Code reviews are a bottleneck. Engineering teams lose measurable velocity waiting for feedback. This delay compounds when security vulnerabilities escalate: defects caught late cost orders of magnitude more to fix than those caught at design time.
AI in CI/CD augments human review by analyzing code patterns and tool outputs before human reviewers see the changes.
Table of contents
Contents
- What Is the Real Cost of Manual Code Review?
- How Does AI Integration Work Without Prompt Injection Risk?
- How Do Tier 2 and Tier 3 Balance Speed Against Security?
- How Does Uncontrolled AI Analysis Become a Security Risk?
- What Outcomes Does AI-Augmented CI/CD Deliver?
- How Do You Get Started With AI-Augmented CI/CD?
- References
What Is the Real Cost of Manual Code Review?
The Review Bottleneck
Development velocity correlates with code review latency. Code review bottlenecks are well-documented across engineering teams. Feedback loops stretch from hours to days while developers context-switch or wait on reviewers. Research from Forsgren et al. (2024) shows context-switching during code review significantly reduces developer productivity and satisfaction.
GitHub’s 2024 Octoverse reports median time from PR open to first review is 4 hours in large organizations, 22 hours in enterprises.
Traditional CI/CD pipelines run automated linters and security scanners, generate reports, then stop. A human reads the output, interprets it, decides if it matters, and either approves or comments. This handoff creates velocity bottlenecks. Eight-hour review windows delay production deployments. Critical insights get buried in noise. Studies confirm developers fear review delays will slow delivery, even though they recognize reviews’ long-term quality benefits (Santos et al., 2024). The cost of this wait scales with engineer compensation.
The Security Cost Multiplier
Security defects amplify this cost multiplier. Boehm & Basili (2001) document that the cost multiplier is phase-dependent, rising from single-digit factors at design time to two or more orders of magnitude at production; Tassey (2002) corroborates these findings at the systems level. The expenses compound: rework costs, deployment delays, and potential security incidents each add to the total as the defect progresses through the pipeline.
Shift-left automation detects issues before a PR merges, before human review begins. AI analyzes linter output, security scan results, and code patterns in seconds. Developers receive immediate feedback, iterate faster, and ship with higher confidence.
The Prompt Injection Risk
Raw AI analysis of code diffs introduces a critical vulnerability: prompt injection. If a CI/CD pipeline feeds user-submitted code directly to an AI model, an attacker can craft a PR with embedded instructions that manipulate the AI’s behavior. The AI might approve malicious code, disable security checks, or expose sensitive information. This is not theoretical. It represents a live attack surface in every AI-augmented system.
Defensive architecture mitigates this risk. The AI analyzes tool output (structured, deterministic results from linters, security scanners, and static analysis) rather than untrusted input directly. The pipeline sequence: linter runs first, generates JSON, AI summarizes the findings, human approves. This removes the direct injection vector, though structured output can still carry adversarially crafted content via file paths or error message text (OWASP, 2025).
Threat models vary by repository type. A private repository with a trusted five-person team tolerates different risk than open-source projects accepting external contributors. Three security tiers match different threat models while maintaining analysis speed.
How Does AI Integration Work Without Prompt Injection Risk?
Tier 1 eliminates prompt injection risk. The linter runs first, produces JSON output, and the AI analyzes only that structured data. The AI never sees the raw code, never processes user input, and never runs in the context of potentially malicious diffs. Using an independent review instance, one without prior context from code generation, is the recommended architectural pattern; a session that wrote the code carries implicit context that can suppress contradictory findings during self-review.
name: AI Analysis - Maximum Security
on: [pull_request]
permissions:
contents: read
jobs:
analyze:
runs-on: ubuntu-24.04
steps:
- name: Checkout
uses: actions/checkout@de0fac2e4500dabe0009e67214ff5f5447ce83dd # v6.0.2
- name: Lint Code
run: pipx run ruff check --output-format=json . > lint.json || exit 0
- name: Setup Goose
uses: clouatre-labs/setup-goose-action@35f35c3a8f08aa333486693114938ec643bf8310 # v1.0.7
- name: AI Analysis
env:
GOOGLE_API_KEY: ${{ secrets.GOOGLE_API_KEY }}
run: |
echo "Summarize these linting issues:" > prompt.txt
cat lint.json >> prompt.txt
# Only structured tool output appended. Never raw source code.
goose run --instructions prompt.txt --no-session --quiet > analysis.md
- name: Upload Analysis
uses: actions/upload-artifact@bbbca2ddaa5d8feaa63e36b76fdaad77386f024f # v7.0.0
with:
name: ai-analysis
path: analysis.mdtier1-maximum-security.ymlCode Snippet 1: In Tier 1, AI analyzes only JSON output from the linter, never raw code. Full example
Pinning actions to a commit SHA rather than a floating tag is a supply chain control, not a style preference. In March 2026, the Trivy ecosystem supply chain was briefly compromised (CVE-2026-33634): an attacker force-pushed 76 version tags in aquasecurity/trivy-action to point to credential-stealing code, and every workflow using a floating tag silently executed the malicious version. A SHA reference is immutable, so tag mutation has no effect. The maintenance burden is minimal: Renovate and Dependabot both open automated PRs to bump pinned SHAs when upstream releases a new version, so staying current requires only a one-click merge.
The AI sees only JSON. No code, no comments, no user input. Attack surface is minimal, but file paths and error strings in JSON output remain a residual indirect-injection vector (OWASP, 2025). This pattern applies to public repositories, open-source projects, and any system where external contributors submit PRs.
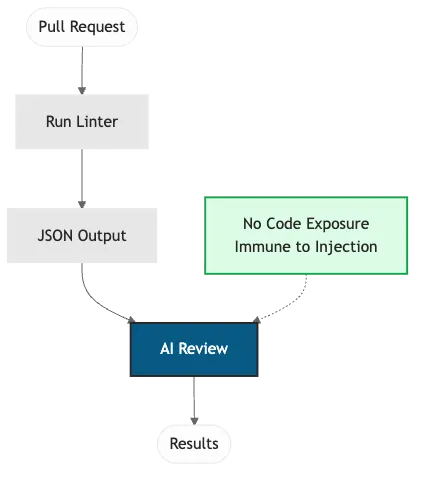
Figure 1: Tier 1 defensive pattern. AI analyzes tool output, never sees raw code. Immune to prompt injection.
How Do Tier 2 and Tier 3 Balance Speed Against Security?
Tier 2 provides additional context (file paths, change stats, commit metadata) without exposing raw code. This represents a middle ground: more insight than Tier 1, lower risk than Tier 3.
name: AI Analysis - Balanced Security
on: [pull_request]
permissions:
contents: read
jobs:
analyze:
runs-on: ubuntu-24.04
steps:
- name: Checkout
uses: actions/checkout@de0fac2e4500dabe0009e67214ff5f5447ce83dd # v6.0.2
- name: Get Changed Files
id: files
run: |
git diff --name-only origin/main...HEAD > files.txt
wc -l files.txt >> summary.txt
- name: Setup Goose
uses: clouatre-labs/setup-goose-action@35f35c3a8f08aa333486693114938ec643bf8310 # v1.0.7
- name: AI Analysis
env:
GOOGLE_API_KEY: ${{ secrets.GOOGLE_API_KEY }}
run: |
echo "Review these file changes:" > prompt.txt
cat files.txt summary.txt >> prompt.txt
# File names and stats. Not the actual code content.
goose run --instructions prompt.txt --no-session --quiet > analysis.md
- name: Upload Analysis
uses: actions/upload-artifact@bbbca2ddaa5d8feaa63e36b76fdaad77386f024f # v7.0.0
with:
name: ai-analysis
path: analysis.mdtier2-balanced-security.ymlCode Snippet 2: In Tier 2, AI sees file scope and metadata, but not code diffs. Full example
The AI sees file-level patterns but not line-by-line changes. Injection risk is low but non-zero: an attacker could craft filenames or commit messages to manipulate analysis. This tier applies to private repositories with trusted contributors.
Tier 3 applies to small, trusted teams where analysis speed outweighs defense-in-depth requirements. The AI sees full code diffs. Injection risk exists but is controlled through human approval gates.
name: AI Analysis - Advanced Patterns
on: [pull_request]
permissions:
contents: read
jobs:
analyze:
runs-on: ubuntu-24.04
steps:
- name: Checkout
uses: actions/checkout@de0fac2e4500dabe0009e67214ff5f5447ce83dd # v6.0.2
- name: Get Full Diff
run: git diff origin/main...HEAD > changes.diff
- name: Setup Goose
uses: clouatre-labs/setup-goose-action@35f35c3a8f08aa333486693114938ec643bf8310 # v1.0.7
- name: AI Analysis
env:
GOOGLE_API_KEY: ${{ secrets.GOOGLE_API_KEY }}
run: |
echo "Deeply analyze these code changes:" > prompt.txt
cat changes.diff >> prompt.txt
# Complete code diffs for maximum context and detail
goose run --instructions prompt.txt --no-session --quiet > analysis.md
- name: Upload Analysis
uses: actions/upload-artifact@bbbca2ddaa5d8feaa63e36b76fdaad77386f024f # v7.0.0
with:
name: ai-analysis
path: analysis.mdtier3-advanced-patterns.ymlCode Snippet 3: In Tier 3, AI sees full diffs for subtle patterns. Full example
Each tier trades visibility for security. Tier 1 eliminates injection risk by sacrificing some context. Tier 2 accepts low risk for moderate context. Tier 3 prioritizes insight over security and is typically used sparingly.
Tier selection depends on three factors:
- Repository access model (external contributors vs internal team)
- Required AI context (tool output vs full diffs)
- Risk tolerance (injection risk vs deeper analysis)
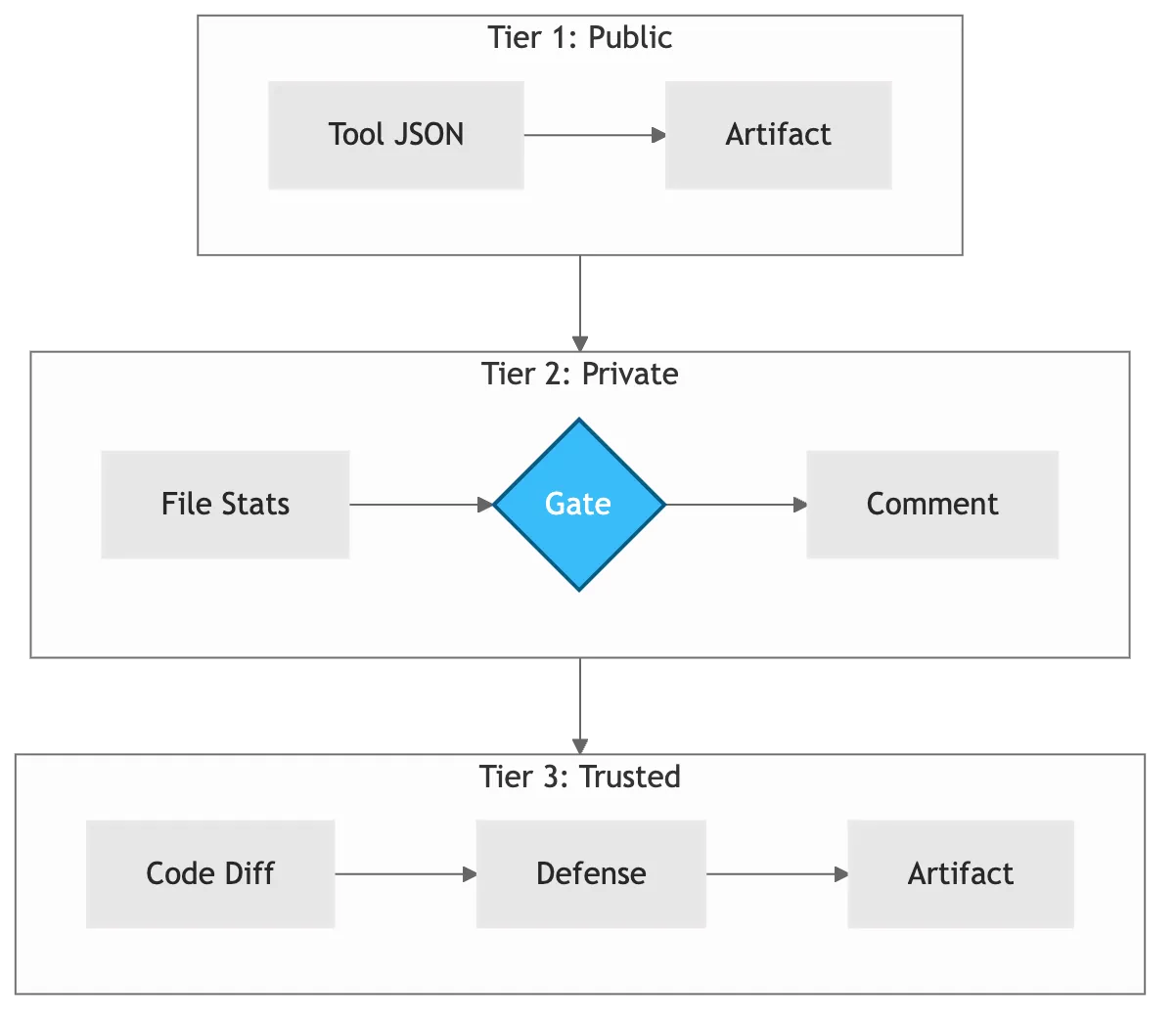
Figure 2: Three security tiers. Selection depends on threat model and team trust level.
| Tier | Input | Injection Risk | Approval Gate | Recommended For |
|---|---|---|---|---|
| 1 | Tool output (JSON) | None | Human reviews artifact | Public repos, OSS, any external contributors |
| 2 | File stats + metadata | Low | Human pre-approval | Private repos, internal teams |
| 3 | Full code diff | Controlled | Optional | Tiny trusted teams only |
Table 1: Tier comparison: security, risk, and recommended use.
The decision framework is simple: start at Tier 1. Measure deployment velocity, security posture, and developer satisfaction. Only move to Tier 2 or 3 if team consensus is that the additional AI context outweighs the injection risk. Most teams never need to leave Tier 1.
How Does Uncontrolled AI Analysis Become a Security Risk?
The naive approach feeds AI the code diff directly and allows it to comment on the PR. This is fast, appears intelligent, and creates an injection surface. The improved approach layers security tiers on top, providing a decision framework that matches the threat model.
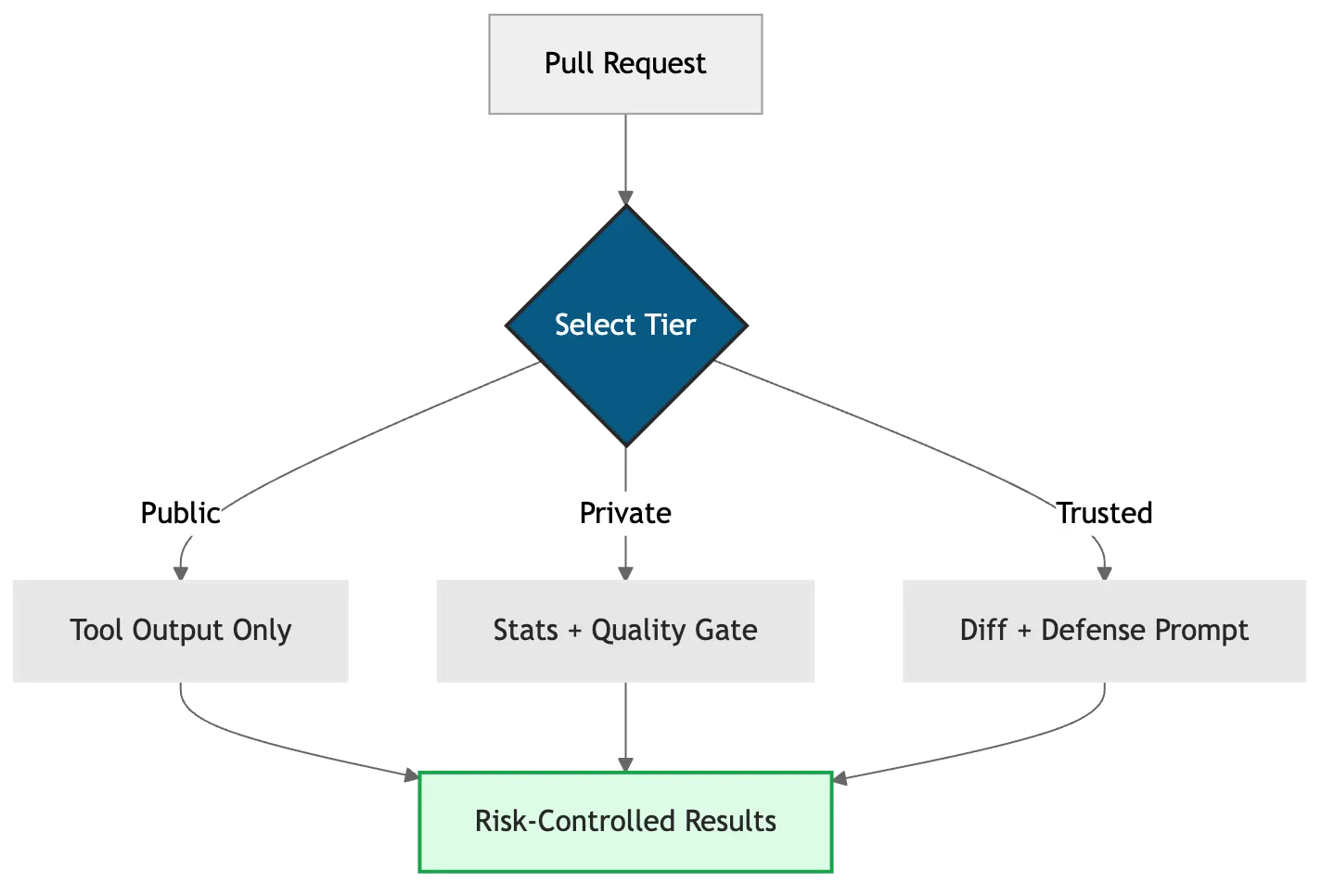
Figure 3: Evolution from uncontrolled AI analysis to risk-managed tiers.
| Dimension | Uncontrolled AI | Managed AI (Tiered) |
|---|---|---|
| Input to AI | Full code diffs, commit messages, PR context | Structured tool output (Tier 1) or metadata (Tier 2) |
| Decision Authority | AI suggests, human reviews comments | AI analyzes, human approves before action |
| Injection Surface | High (user-submitted code in prompt) | Minimal to none (tool output only in Tier 1) |
| Applicable Context | Small trusted teams only | All team sizes and trust models |
Table 2: Architectural comparison: uncontrolled vs. managed AI analysis.
The shift is architectural, not just operational. The evolution moves from “AI sees everything and decides” to “AI sees what’s safe and humans decide what matters.” This distinction enables both security and speed improvements.
What Outcomes Does AI-Augmented CI/CD Deliver?
Human first-review latency runs 4–22 hours in large organizations (Graphite, “State of Code Review 2024”); in our implementation, AI analysis completes in 2–7 seconds, a reduction of three to four orders of magnitude compared to that baseline. Developers iterate faster because they receive feedback immediately. CI/CD pipelines do not stall waiting for human review availability.
AI flags issues during windows when human attention degrades: late-night reviews, context-switching mid-sprint. Linting issues get flagged automatically. Security tool outputs get analyzed for severity and context. Fewer critical issues reach production because they are caught earlier in the workflow.
For broader observability patterns in AI agent workflows, including legacy system integration, see AI agents in legacy systems.
Developer satisfaction increases when velocity and quality both improve. Engineers are not blocked by the review process. They receive comprehensive feedback without waiting. They trust the pipeline because it combines deterministic tools with AI insight and human judgment.
The expected directional outcomes, higher deployment frequency, lower mean time to resolution, fewer security incidents, follow directly from the mechanisms described above. Baseline measurement before integration is the only reliable way to confirm these trends in a given environment.
How Do You Get Started With AI-Augmented CI/CD?
Start With Tier 1
Start with Tier 1. It provides maximum security with zero prompt injection risk. The example workflow demonstrates the complete pattern. As of v1.0.7, the action verifies the Goose binary against its SLSA provenance attestation before installation, and the project holds an OpenSSF Best Practices Silver badge, a level reached by fewer than 1% of open-source projects. For AWS-native environments, setup-kiro-action offers SIGV4 authentication without API keys in secrets.
Tier selection depends on threat model. External contributors and public repositories warrant Tier 1. Internal teams with trusted code may benefit from Tier 2 or Tier 3 context. The key is matching exposure level to trust level.
Measure Before You Integrate
Baseline measurement establishes the starting point: current review latency, deployment frequency, and security incident rate. A two-week measurement period provides sufficient data for comparison. After AI integration, the same metrics reveal impact.
The human gate remains essential throughout. AI generates artifacts for review, not merge approvals. Engineers validate recommendations before acting. This preserves accountability while accelerating feedback cycles.
Tune for Signal Quality
Explicit review criteria improve signal quality. Define which issue categories the AI should report (bugs, security vulnerabilities, API misuse) and which to skip (minor style preferences or project-local conventions). Vague instructions like “be thorough” produce high false-positive rates that erode developer trust across all finding categories.
On re-runs after new commits, pass prior findings in context and instruct the AI to report only new or still-unaddressed issues. This prevents duplicate comments from accumulating on long-lived PRs. For large PRs spanning many files, split the review into a per-file local analysis pass followed by a separate cross-file integration pass. Reviewing everything in a single prompt overloads context and produces contradictory findings (Anthropic, “Best Practices for Claude Code”, 2026).
Give the AI Project Context
An AGENTS.md file at the repository root is the idiomatic mechanism for providing project-level context (testing standards, review criteria, fixture conventions) to CI-invoked AI without modifying prompts per workflow. Whether those gains materialise at the expected magnitude depends on how precisely the review criteria and context files are configured. The infrastructure exists; the constraint is configuration discipline.
For observability patterns in AI agent workflows, see AI Observability Gaps.
References
- Anthropic, “Best Practices for Claude Code” (2026) - https://code.claude.com/docs/en/best-practices
- Boehm & Basili, “Software Defect Reduction Top 10 List” (2001) - https://www.cs.umd.edu/projects/SoftEng/ESEG/papers/82.78.pdf
- Forsgren et al., “DevEx in Action: A study of its tangible impacts” (2024) - https://dl.acm.org/doi/10.1145/3639443
- Graphite, “State of Code Review 2024” - https://static.graphite.dev/Graphite_State_of_code_review_2024.pdf
- GitHub Advisory Database, “Trivy ecosystem supply chain was briefly compromised” CVE-2026-33634 (2026) - https://github.com/advisories/GHSA-69fq-xp46-6x23
- OWASP LLM Top 10 (2025 edition), Prompt Injection LLM01 - https://genai.owasp.org/llmrisk/llm01-prompt-injection/
- Santos et al., “Modern code review in practice: A developer-centric study” (2024) - https://www.sciencedirect.com/science/article/pii/S0164121224003327
- Tassey, G., “The Economic Impacts of Inadequate Infrastructure for Software Testing,” NIST (2002) - https://www.nist.gov/system/files/documents/director/planning/report02-3.pdf